- Overview
- Configuration
- Technical
-
RFC 1305
- 1. Introduction
- 1.1 Related Technology
- 2. System Architecture
- 2.1 Implementation Model
- 2.2 Network Configurations
- 3. Network Time Protocol
- 3.1 Data Formats
- 3.2 State Variables and Parameters
- 3.3 Modes of Operation
- 3.4 Event Processing
- 3.4.1 Notation Conventions
- 3.4.2 Transmit Procedure
- 3.4.3 Receive Procedure
- 3.4.4 Packet Procedure
- 3.4.5 Clock-Update Procedure
- 3.4.6 Primary-Clock Procedure
- 3.4.7 Initialization Procedures
- 3.4.7.1 Initialization Procedure
- 3.4.7.2 Initialization-Instantiation Procedure
- 3.4.7.3 Receive-Instantiation Procedure
- 3.4.7.4 Primary Clock-Instantiation Procedure
- 3.4.8 Clear Procedure
- 3.4.9 Poll-Update Procedure
- 3.5 Synchronization Distance Procedure
- 3.6 Access Control Issues
- 4. Filtering and Selection Algorithms
- 4.1 Clock-Filter Procedure
- 4.2 Clock-Selection Procedure
- 4.2.1 Intersection Algorithm
- 4.2.2. Clustering Algorithm
- 5. Local Clocks
- 5.1 Fuzzball Implementation
- 5.2 Gradual Phase Adjustments
- 5.3 Step Phase Adjustments
- 5.4 Implementation Issues
- 6. Acknowledgments
- 7. References
- Appendix A
- Appendix B
- Appendix C
- Appendix D
- Appendix E
- Appendix F
- Appendix G
- Appendix H
- Appendix I
- About
- Time Tools
| Previous Top Next |
Windows Time Client
4. Filtering and Selection AlgorithmsA most important factor affecting the accuracy and reliability of time distribution is the complex of algorithms used to reduce the effect of statistical errors and falsetickers due to failure of various subnet components, reference sources or propagation media. The algorithms suggested in this section were developed and refined over several years
of operation in the Internet under widely varying topologies, speeds and traffic regimes. While these algorithms are believed the best available at the present time, they are not an integral part of the NTP specification, since other algorithms with similar or superior performance may be devised in future.
However, it is important to observe that not all time servers or clients in an NTP synchronization subnet must implement these algorithms. For instance, simple workstations may dispense with one or both of them in
the interests of simplicity if accuracy and reliability requirements justify. Nevertheless, it would be expected that an NTP server providing synchronization to a sizable community, such as a university campus or research laboratory, would be expected to implement these algorithms or others proved to have equivalent functionality. A comprehensive
discussion of the design principles and performance is given in [MIL91a].
In order for the NTP filter and selection algorithms to operate effectively, it is useful to have a measure of recent sample variance recorded for each peer. The measure adopted is based on first-order differences, which are easy to compute and effective for the purposes intended. There are two measures, one called the filter dispersion
epsilonsigma and the other the select dispersion epsilonxi. Both are computed as the weighted sum of the clock offsets in a temporary list sorted by synchronization distance. If thetai (0 <= i < n) is the offset of the ith entry, then the sample difference epsiloij of the ith entry relative to the jth entry is defined epsilonij = | thetai - thetaj | . The dispersion relative to the jth entry is defined epsilonj and computed as the weighted sum
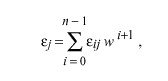
where w is a weighting factor chosen to control the influence of synchronization distance in the dispersion budget. In the NTP algorithms w is chosen less than 1 / 2 : w = NTP.FILTER for filter dispersion and w = NTP.SELECT for select dispersion. The (absolute) dispersion epsilonsigma and epsilonxi as used in the NTP algorithms are defined relative to the 0th entry epsilon0.
There are two procedures described in the following, the clock-filter procedure, which is used to select the best offset samples from a given clock, and the clock-selection procedure, which is used to select the best clock among a hierarchical set of clocks.